Using Keras’ Pre-trained Models for Feature Extraction in Image Clustering

Keras provides a set of state-of-the-art deep learning models along with pre-trained weights on ImageNet. These pre-trained models can be used for image classification, feature extraction, and transfer learning. This post describes a study about using some of these pre-trained models in clustering a subset of dog/cat images from Kaggle and Microsoft. Our approach consists of three major components:
- Using a pre-trained model in Keras, e.g., VGG, to extract the feature of a given image;
- Using kMeans in Scikit-Learn to cluster a set of dog/cat images based on their corresponding features;
- Using Silhouette Coefficient and Adjusted Rand Index in Scikit-Learn to evaluate the performance of the clustering method.
Along the road, we will compare and contrast the performance of four pre-trained models (i.e., VGG16, VGG19, InceptionV3, and ResNet50) on feature extraction, and the selection of different numbers of clusters for kMeans in Scikit-Learn.
1. Using a pre-trained model in Keras to extract the feature of a given image
Let’s consider VGG as our first model for feature extraction. VGG is a convolutional neural network model for image recognition proposed by the Visual Geometry Group at the University of Oxford, where VGG16 refers to a VGG model with 16 weight layers, and VGG19 refers to a VGG model with 19 weight layers. Fig. 2 illustrates the architecture of VGG16: the input layer takes an image in the size of (224 x 224 x 3), and the output layer is a softmax prediction on 1000 classes. From the input layer to the last max pooling layer (labeled by 7 x 7 x 512) is regarded as the feature extraction part of the model, while the rest of the network is regarded as the classification part of the model.
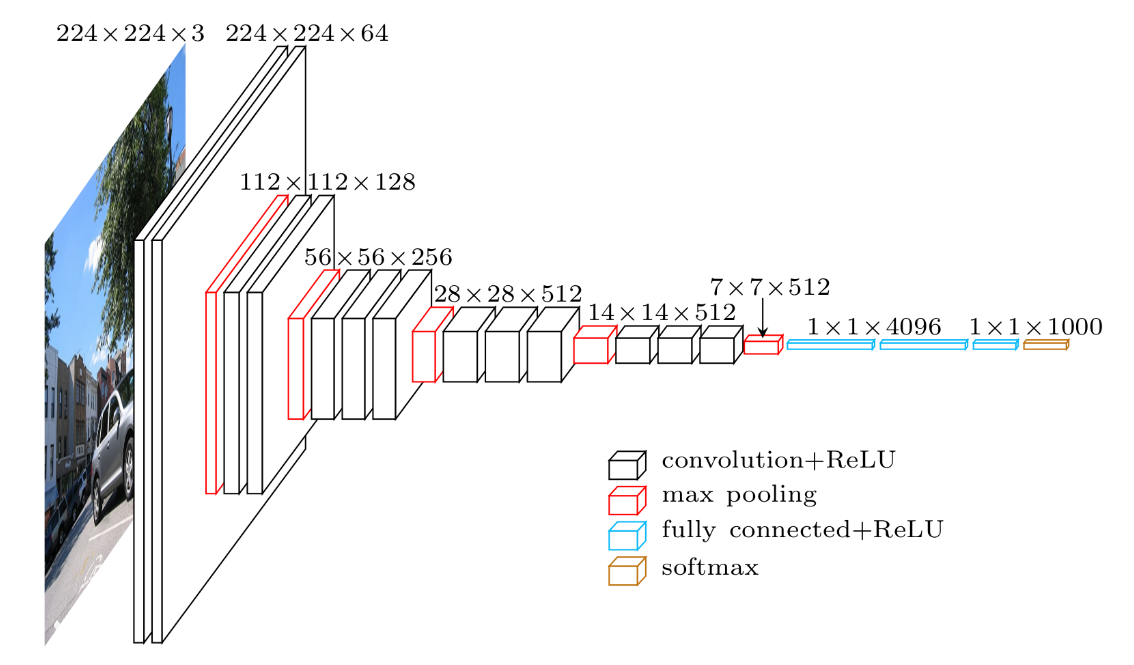
Fig. 3 shows a program in Keras taking an image and extracting its feature. Fig. 4 shows the shape of the feature as (1L, 7L, 7L, 512L) which is identical to the output of the feature extractor mentioned above. (Note: This program is for feature extraction, not for image classification. Please check classify ImageNet classes for predicting the corresponding classes.)
2. Using kMeans in Scikit-Learn to cluster a set of images
Fig. 5 shows the program iterating a set of images and collecting their features into a list, then applying kMeans in Scikit-Learn to cluster the features.
There are two important issues in applying kMeans in Scikit-Learn to this clustering problem. First, note that Line 18 in Fig. 5 uses numpy.ndarray.flatten to collapse a feature from the model (where different pre-trained models produce different shapes of features as listed below) into a one-dimension array required by kMeans in Scikit-Learn (where the input shape is [n_samples, n_features]).
- VGG16 feature shape — (1L, 7L, 7L, 512L)
- VGG19 feature shape — (1L, 7L, 7L, 512L)
- InceptionV3 feature shape — (1L, 5L, 5L, 2048L)
- ResNet50 feature shape — (1L, 1L, 1L, 2048L)
Second, note that Line 21 in Fig. 5 defines 2 clusters as a parameter to kMeans in Scikit-Learn, which matches the nature of our dog/cat dataset. However, generally speaking, determining the number of clusters in a data set, or validating the assumption of our magic number, is a crucial step in solving a clustering problem [wiki]. We will use silhouette coefficient to determine the number of clusters and compare and contrast different pre-trained models later.
3. Evaluating the performance of different clustering methods
We will consider two approaches to evaluate the performance of different clustering methods: [ref1, ref2]
- Internal Cluster Validation: investigating the structure of clustering results without information outside of the dataset, i.e., without the known labels. We will use Silhouette Coeffecient in Scikit-Learn for internal cluster validation. The measure is bounded between -1 for incorrect clustering and 1 for highly dense clustering. Scores around zero indicate overlapping clusters.
- External Cluster Validation: comparing the results of a cluster method with the known labels. We will use Adjusted Rand Index in Scikit-Learn for external cluster validation. The range of scores is between -1 and 1, where negative values mean that the predicted clusters and the known clusters are highly different, positive values mean that the predicted clusters and the known clusters are similar, and 1 is the perfect match score.
First of all, let’s consider the case of internal cluster validation, together with the selection of numbers of clusters, in clustering 1000 dog images and 1000 cat images.
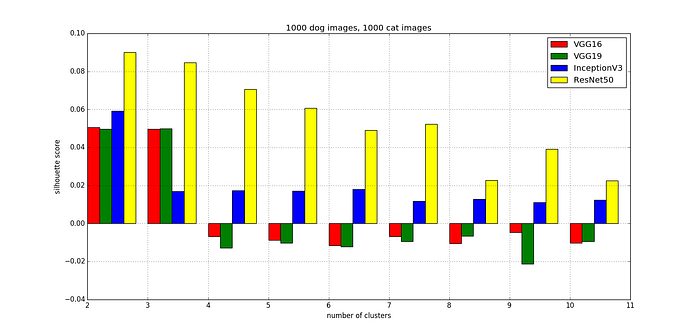
Fig. 6 shows the silhouette scores with different numbers of clusters (between 2 and 10) under 4 different pre-rained models (VGG16, VGG19, InceptionV3, and ResNet50).
- The silhouette scores of ResNet50 (the yellow bars) show that using 2 clusters under kMeans in Scikit-Learn has the highest score. This indicates that assigning k in kMeans as 2 is the best case.
- The silhouette scores of InceptionV3 (the blue bars) also show that assigning k in kMeans as 2 is the best case.
- However, the silhouette scores of VGG16 (the red bars) and the silhouette scores of VGG19 (the green bars) both show that it is a close call between using 2 clusters and using 3 clusters.
- Cross-examining the scores of different models under different clusters, ResNet50 always has the highest scores. Generally speaking, InceptionV3 is in the second place, and VGG16/VGG19 are in the third/fourth places.
In summary, ResNet50 under 2 clusters is the best feature extractor in our case. However, does the test of internal cluster validation agree with the test of external cluster validation?
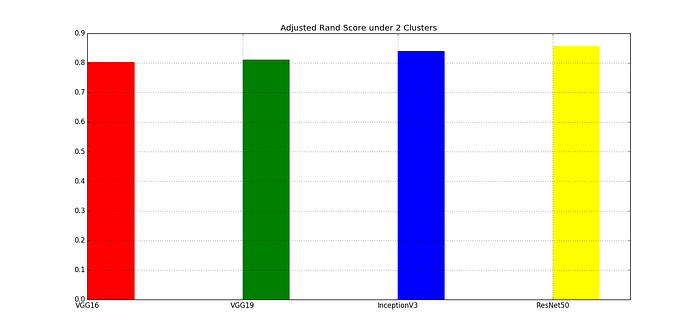
Fig. 7 shows the Adjusted Rand Index scores with 2 clusters under 4 different models. Recall that Adjusted Rand Index indicates the similarity between the predicted clusters and the known labels in the ground truth, Fig.7 shows that ResNet50 achieves the first place, InceptionV3 achieves the second place, and VGG16/VGG19 are in the third/fourth places. So, internal cluster validation does agree with external cluster validation.
4. Conclusions
This post presents a study about using pre-trained models in Keras for feature extraction in image clustering. We have investigated the performance of VGG16, VGG19, InceptionV3, and ResNet50 as feature extractors under internal cluster validation using Silhouette Coefficient and external cluster validation using Adjusted Rand Index. Image clustering is definitely an interesting challenge. I hope this post has described the basic framework for designing and evaluating a solution for image clustering. If you have any questions or suggestions, please leave a comment.
5. References
[1] Using pre-trained models in Keras.
[2] An Overview of ResNet and its Variants.
[3] Selecting the number of clusters with silhouette analysis on kMeans clustering.
[4] Getting Started with Orange 14: Image Analytics — Clustering.
